Des origines d’Internet au Web (1.0)

Le Web (ou World Wide Web) n’est pas Internet. C’est un des systèmes fonctionnant sur le réseau « Internet ».
Le Web permet de consulter, avec un navigateur, des pages accessibles sur des sites via des adresses singulières et uniques, les URLs (*Uniform Resource Locator*) qui s’affichent dans la barre d’adresse et commençant par « http:// » (Hyper Text Transfert Protocole) ou « https:// » pour utiliser une connexion chiffrée entre le navigateur et le serveur.
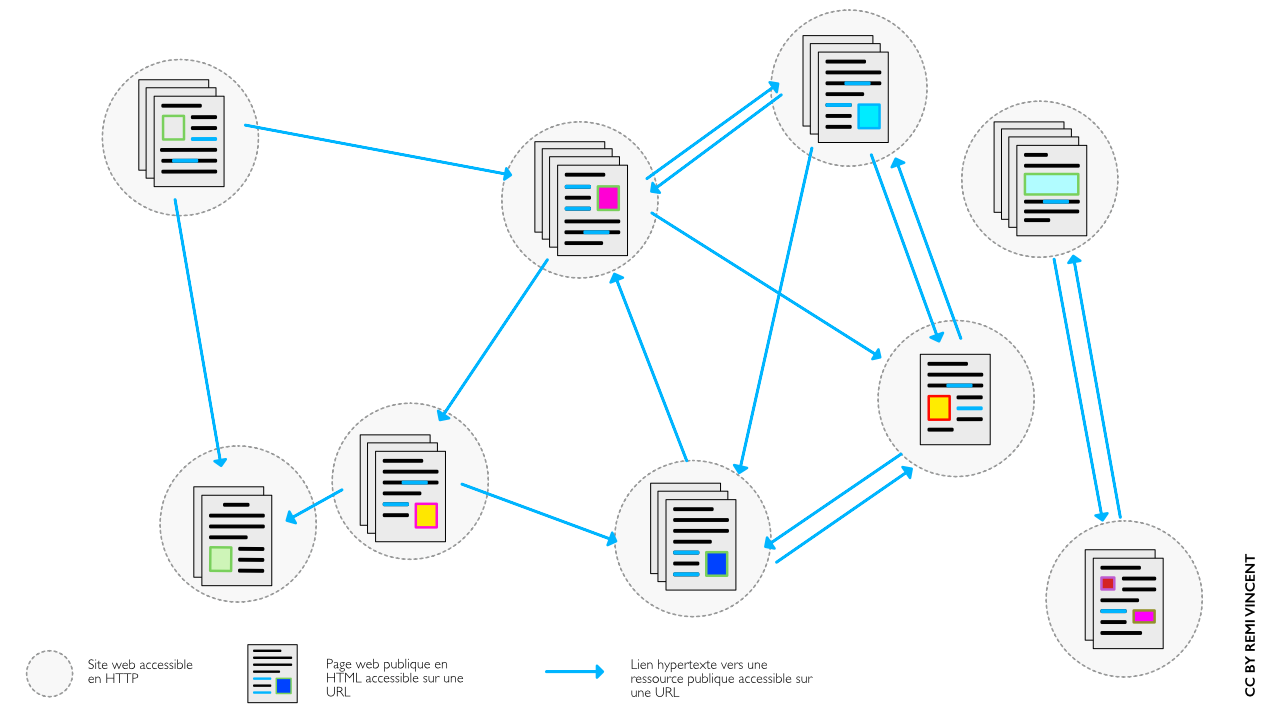
L’image de la toile d’araignée vient des hyperliens qui relient les pages web entre elles.
Le Web ne pourrait pas existant sans Internet.

Sir Tim Berners Lee, inventeur du World Wide Web, et Vinton Cerf, « père » du TCP-IP protocole permettant le fonctionnement d’Internet
## Un concept imaginé il y a près de 100 ans
En 1930, [Paul Otlet](https://fr.wikipedia.org/wiki/Paul_Otlet) souhaite créer un réseau international de bibliothèques interconnectées en utilisant les capacités nouvelles de communication qui ont vu le jour quelques années avant et dont les usages se démocratisent petit à petit.
L’idée originelle est d’utiliser un téléphone avec lequel il serait possible d’appeler une bibliothèque sans avoir à s’y rendre physiquement et de demander la lecture d’un ouvrage en particulier ; puis il imagine un système reposant sur une sorte de visionneuse à distance permettant directement la lecture du support.
Cette idée ne verra pas le jour à l’époque mais le concept de la mise à disposition de ressources publiques consultables à distance est bel et bien déjà là et est considérée aujourd’hui comme étant à l’origine d’Internet, puis du Web.
Par la suite, en 1961, lors du XXIIéme congrès du Parti Communiste soviétique, dans un objectif de centralisation et de mise à disposition des informations, des discussions ont lieu pour imaginer la connexion des données en réseau. Ces échanges ne déboucheront pas sur des suites viables compte tenu de l’hétérogénéité des systèmes en places.
### La légende du Spoutnik à l’origine d’Internet

Timbre soviétique commémoratif (Wikimedia)
En 1957, en pleine guerre froide, [les Soviétiques surprennent le monde entier](https://fr.wikipedia.org/wiki/Crise_du_Spoutnik), et en particulier les Américains, en envoyant les premiers un satellite artificiel dans l’espace, le célèbre [Spoutnik](https://fr.wikipedia.org/wiki/Spoutnik).
Pour reprendre la main, D. Eiseinhower, alors Président des Etats-Unis, créé dès 1958 [l’Arpa (*Advanced research projects agency*)](https://fr.wikipedia.org/wiki/Defense_Advanced_Research_Projects_Agency) au sein du Département de la Défense pour développer des innovations technologiques pour l’armée puis la [NASA](https://fr.wikipedia.org/wiki/National_Aeronautics_and_Space_Administration) pour reprendre la main dans la conquête spatiale.
L’Arpa va chercher, entre autre projet, à faire communiquer des ordinateurs entre eux via des lignes téléphoniques.
La légende voudrait que l’idée de ce réseau aurait vu le jour pour répondre à l’objectif d’organiser la défense américaine et qu’il soit conçu originellement pour résister à une attaque nucléaire en étant décentralisé, mais le principal usage sera pour le partage de travaux et l’échange d’informations entre scientifiques.
## La naissance d’internet
En septembre 1969, après 12 ans de recherche et d’expérimentations, [ARPA-Network](https://fr.wikipedia.org/wiki/ARPANET) voit le jour. C’est un réseau informatique constitué de deux ordinateurs entre l’UCLA (Université de Californie) et Standford, à Los Angeles.
> A 22h30, le 29 octobre 1969, le premier message envoyé est le mot « login » (connexion) mais comme le système plante à la troisième lettre, le premier message de l’histoire d’internet se résumera à « lo ».
>
> Anecdote
Il s’étend à quatre ordinateurs, dès le mois de décembre 1969 avec la connexion de l’Université de l’Utah et de l’Université de Californie de Santa-Barbara. **« Arpanet »est ainsi l’ancêtre d’internet. **Il va s’étendre petit à petit à l’ensemble du territoire américain.
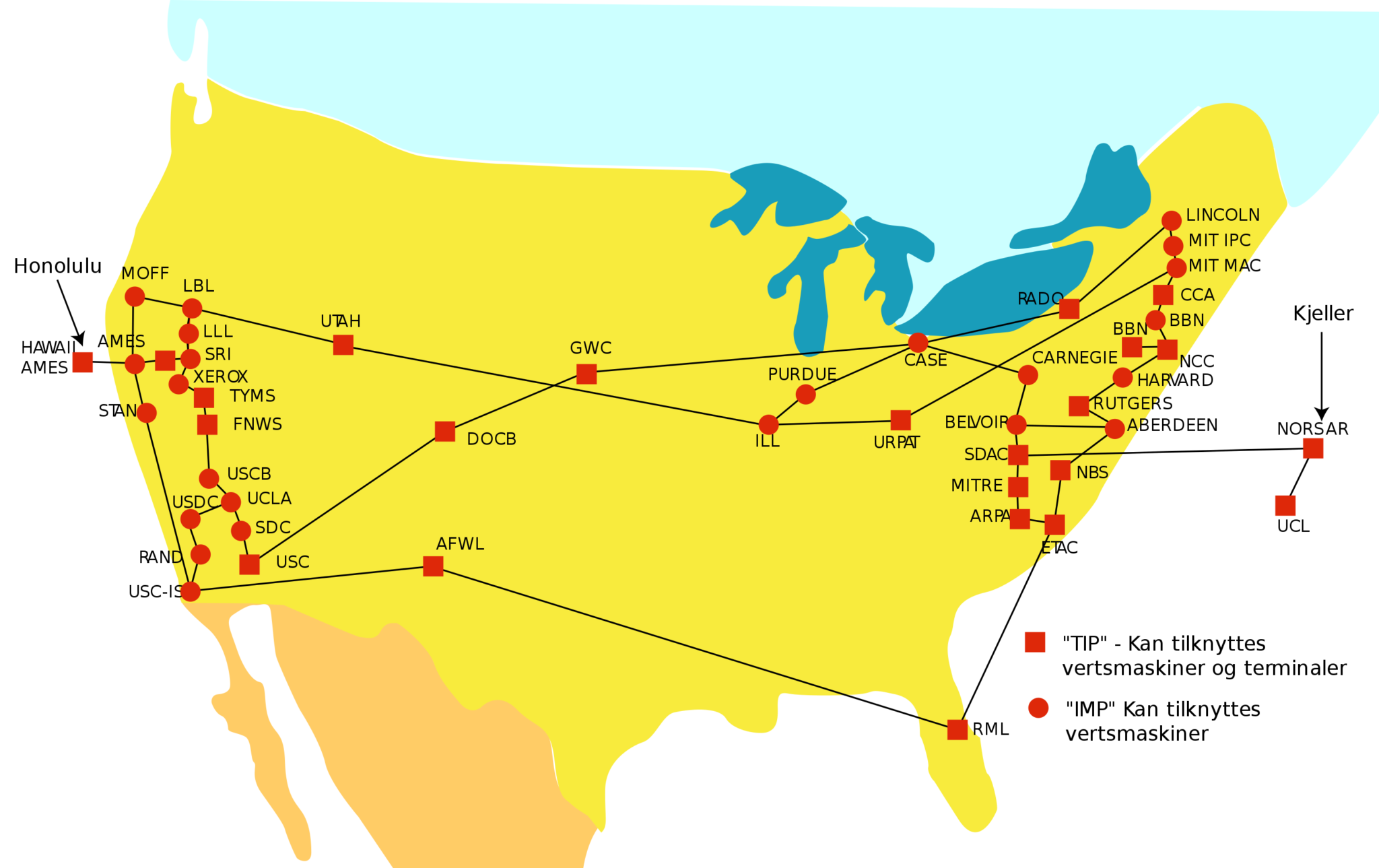
Carte d’ARPANET en 1974 (Wikimedia)
En parallèle, vont se développer d’autres expérimentations de mise en réseau, que ce soit aux Etats-Unis ou ailleurs dans le monde et en particulier en Europe.
### D’ARPANet à InterNet
Compte tenu qu’ARPANet a été développé par des universitaires, et non des militaires, l’armée américaine et la DARPA, vont scinder les usages pour permettre des développements différents, l’un militaire, l’autre civil.
Ainsi à partir de 1980, différents réseaux universitaires et publics vont être interconnectés avec le réseau originel ARPANet pour donner naissance à InterNet (Interconnected Network).
D’autres réseaux feront de même en parallèle et donneront naissance par exemple à [Usenet](https://fr.wikipedia.org/wiki/Usenet), un réseau de forum encore utilisé aujourd’hui.
En 1974, le [TCP/IP](https://fr.wikipedia.org/wiki/Suite_des_protocoles_Internet) (Transmission Control Protocol et Internet Protocol) voit le jour à l’initiative de Vinton Cerf pour uniformiser le réseau. Ce protocole sera définitivement adopté en 1983 et est toujours utilisé de nos jours.
Face à l’engouement libertaire pour ce nouvel outil de communication, et aux rêves que suscitent ce « cyberespace » supra-national encore quasiment vierge, différentes autorités gouvernementales et économiques cherchent à en réguler les usages ou à en interdire l’accès.
Au début des années 1990, une poignet de pionniers se fédèrent au sein de l’Electronic Frontier Fondation (EFF) alors pour défendre ce « nouveau monde » des velléités de contrôles et de surveillances et la liberté d’expression.
Cette prise de position donne lieu en 1996, à la [déclaration d’indépendance du cyberespace](https://www.cairn.info/libres-enfants-du-savoir-numerique--9782841620432-page-47.htm#) de [John Perry Barlow](https://fr.wikipedia.org/wiki/John_Perry_Barlow).
## Le Web, qu’est ce que c’est alors ?
Le Web n’est qu’une des applications d’Internet, distincte d’autres applications comme le courrier électronique inventé en 1972 par Ray Tomlison, la messagerie instantanée avec IRC par exemple ou encore le transfert de fichiers en pair à pair ou la Voix sur IP.
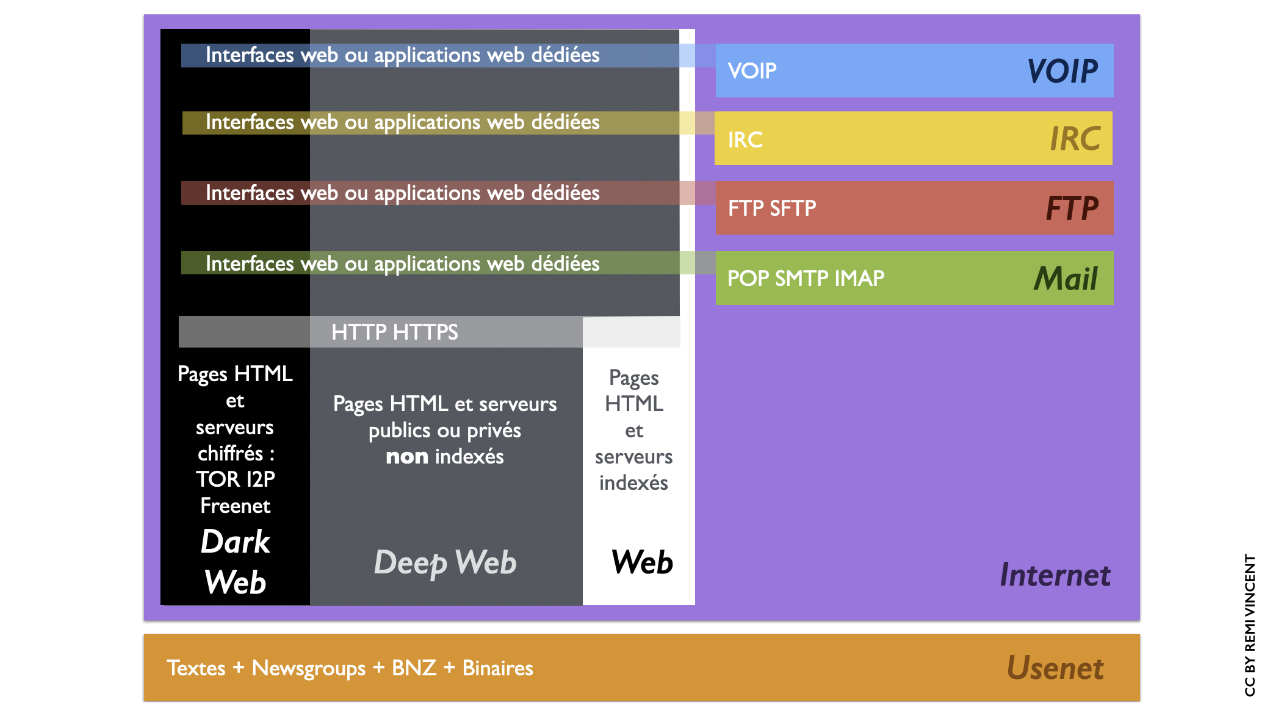
Le Web, dans l’imaginaire du grand public, amalgame trois grands domaines identifiables :
- Le « **Deep Web** » ou Web profond qui représente la majorité des pages web. Il est constitué de pages en HTML (et de serveurs publics ou privés) qui ne sont pas indexées par les différents robots « crawler » des moteurs de recherche : c’est par exemple le cas des pages web avec le détail de vos comptes bancaires mises à disposition par votre banque.
- Le « **Dark Web**« , objet de très nombreux fantasmes, car il n’est accessible que via des protocoles chiffrés spécifiques et est donc particulièrement utilisé par les personnes cherchant à naviguer anonymement… on imagine en priorité les délinquants et cyber-criminels. Mais il est aussi particulièrement utile pour les opposants politiques ou les lanceurs d’alertes cherchant à contourner la surveillance dont il pourrait faire l’objet de la part de gouvernements ou d’entreprises malfaisantes.
- Enfin le **Web** « public » est celui auxquel nous accédons le plus facilement par le biais d’une recherche sur un moteur de recherche. Avant l’apparition de ces moteurs de recherche, il faillait passer par des annuaires de sites ou connaitre directement l’adresse à visiter.
Aujourd’hui, par le biais d’interfaces web, ou d’applications web dédiées, nous pouvons accéder à de nombreux outils qui fonctionnent sur Internet, comme par exemple avec les « Webmails ».
### Première version du web : 12 Mars 1989
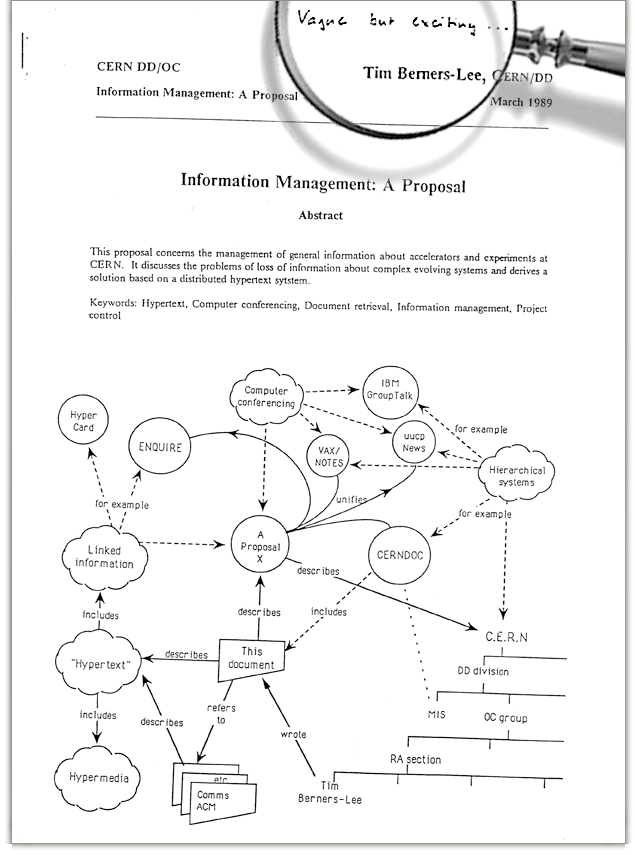
« Vague, mais prometteur ».
Voilà comment Mike Sendall, à l’époque chef de Tim Berners Lee au CERN, commente, de trois mots, le document que l’informaticien britannique lui a soumis.
Un brouillon de quelques pages, sobrement appelé « gestion de l’information : une proposition » dans lequel Tim Berners Lee présente une réorganisation des bases de données du prestigieux centre de recherche nucléaire.
Ce système d’information distribué utiliserait des technologies de consultation non linéaires, notamment l’hypertexte, pour lier les innombrables documents scientifiques du réseau du CERN entre eux
Sans même s’en rendre compte, il vient de poser les bases d’une des plus grandes révolutions technologiques du siècle.
### Le premier site : 20 décembre 1990

NeXT, société nouvellement créé par Steve Jobs (alors renvoyé d’Apple qu’il a créé avec Steve Wozniak en 1976), qui propose les plus puissantes stations de travail pour l’époque.
Accessible à l’adresse <http://info.cern.ch>, le premier site n’est accessible et consultable que sur le réseau interne du CERN.
Il s’appuie sur deux protocoles mis au point avec Robert Caillau :
- HTTP : pour localiser et lier les documents
- HTML : pour créer les pages
Ce premier site est mis à disposition depuis un serveur Web mis au point sur l’ordinateur NeXT que Mike Sendall a offert à Tim Berners Lee.
### le Web s’ouvre à tous : 6 Aout 1991
Tim Berners-Lee annonce le projet sur le groupe alt.hypertext de Usenet – les forums primordiaux d’Internet, où les pionniers échangent déjà depuis 1979 !
Sur le groupe alt.hypertext de Usenet, Tim Bernes lee partage un message présentant son projet de « World Wide Web » et invite tous les utilisateurs d’Internet à l’essayer en téléchargeant un « navigateur » et en accédant à un site de test :
> From: timbl@info .cern.ch (Tim Berners-Lee)
>
> Newsgroups: alt.hypertext
>
> Subject: Re: Qualifiers on Hypertext links…
>
> Message-ID: <6484@cernvax.cern.ch>
>
> Date: 6 Aug 91 14:56:20 GMT
>
> References: <1991Aug2.115241@ardor.enet.dec.com>
>
> Sender: news@cernvax.cern.ch
>
> Lines: 52
>
> In article <1991Aug2.115241@ardor.enet.dec.com> kannan@ardor.enet.dec.com (Nari Kannan) writes:
>
> >
>
> > Is anyone reading this newsgroup aware of research or development efforts in
>
> > the
>
> > following areas:
>
> >
>
> > 1. Hypertext links enabling retrieval from multiple heterogeneous sources of
>
> > information?
>
> The WorldWideWeb (WWW) project aims to allow links to be made to any information anywhere. The address format includes an access method (=namespace), and for most name spaces a hostname and some sort of path. We have a prototype hypertext editor for the NeXT, and a browser for line mode terminals which runs on almost anything. These can access files either locally, NFS mounted, or via anonymous FTP. They can also go out using a simple protocol (HTTP) to a server which interprets some other data and returns equivalent hypertext files. For example, we have a server running on our mainframe (http://cernvm.cern.ch/FIND in WWW syntax) which makes all the CERN computer center documentation available. The HTTP protocol allows for a keyword search on an index, which generates a list of matching documents as annother virtual hypertext document.
>
> If you’re interested in using the code, mail me. It’s very prototype, but available by anonymous FTP from info.cern.ch. It’s copyright CERN but free distribution and use is not normally a problem.
>
> The NeXTstep editor can also browse news. If you are using it to read this, then click on this: <http://info.cern.ch/hypertext/WWW/TheProject.html> to find out more about the project. We haven’t put the news access into the line mode browser yet.
>
> We also have code for a hypertext server. You can use this to make files available (like anonymous FTP but faster because it only uses one connection). You can also hack it to take a hypertext address and generate a virtual hypertext document from any other data you have – database, live data etc. It’s just a question of generating plain text or SGML (ugh! but standard) mark-up on the fly. The browsers then parse it on the fly.
>
> The WWW project was started to allow high energy physicists to share data, news, and documentation. We are very interested in spreading the web to other areas, and having gateway servers for other data. Collaborators welcome! I’ll post a short summary as a separate article.
>
> Tim Berners-Lee timbl@info.cern.ch
>
> World Wide Web project CERN
>
> Tel: +41(22)767 3755 Fax: +41(22)767 7155
>
> 1211 Geneva 23, Switzerland (usual disclaimer)
>
> [Alt-hypertext](https://www.w3.org/People/Berners-Lee/1991/08/art-6484.txt)
Son message commence ainsi : « Le projet World Wide Web fusionne les techniques d’extraction d’information et d’hypertexte pour créer un système d’information global, simple mais puissant. ».
Quelques lignes plus loin, Tim Berners Lee écrit « essayez-le » en fournissant l’adresse pour télécharger un navigateur et l’URL d’un site d’essai.
C’est la première fois que des utilisateurs d’Internet peuvent l’utiliser en dehors du CERN.
Ce message historique peut encore être consulté dans les archives de Google Groups.
## 1993 : le web s’envole
Le lancement du **navigateur Mosaic** fait exploser l’intérêt pour le World Wide Web et le 13 avril 1993, le CERN passe le projet dans le domaine public et publie son code source.
Désormais accessible à tous, gratuit, le Web voit très vite son usage exploser sur Internet.
En un an seulement, on passe de quelques 500 serveurs Web à 10 000 à la fin 1994 !
Le lancement de **Netscape**, le premier navigateur réellement grand public, participera aussi largement à la démocratisation du WWW par la suite.
En quelques années, le Web suscite énormément d’intérêt et en particulier des milieux financiers qui investissent lourdement dans cette nouvelle technologie extrêmement prometteuse ce qui provoquera l’[apparition d’une bulle spéculative](https://fr.wikipedia.org/wiki/Bulle_sp%C3%A9culative_(Internet)) qui implosera à l’aube des années 2000.